Start Recovery を選択して、ストレージノードを設定します
 変更を提案
変更を提案
ストレージノードを交換したら、 Grid Manager で Start Recovery を選択して、障害が発生したノードの代わりとして新しいノードを設定する必要があります。
-
を使用して Grid Manager にサインインする必要があります サポートされている Web ブラウザ。
-
Maintenance または Root Access 権限が必要です。
-
プロビジョニングパスフレーズが必要です。
-
交換用ノードの導入と設定が完了している必要があります。
-
イレイジャーコーディングデータの修復ジョブの開始日を把握しておく必要があります。
-
ストレージノードが過去 15 日以内に再構築されていないことを確認しておく必要があります。
ストレージノードが Linux ホストにコンテナとしてインストールされている場合は、次のいずれかに該当する場合にのみこの手順を実行する必要があります。
-
ノードをインポートするには '--force' フラグを使用する必要がありましたまたは StorageGRID node force-recovery_node-name_ を発行しました
-
ノードの完全な再インストールを実行するか、 /var/local をリストアする必要がありました。
-
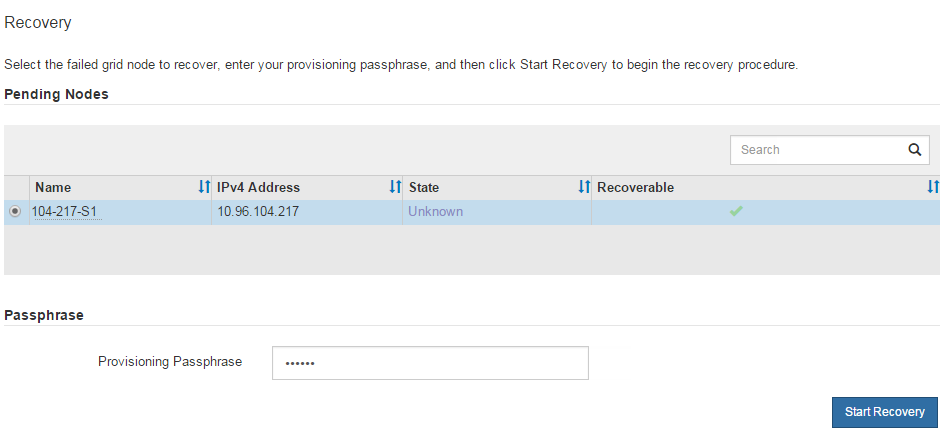
Grid Manager から * maintenance * > * Tasks * > * Recovery * を選択します。
-
リカバリするグリッドノードを Pending Nodes リストで選択します。
ノードは障害が発生するとリストに追加されますが、再インストールされてリカバリの準備ができるまでは選択できません。
-
プロビジョニングパスフレーズ * を入力します。
-
[ リカバリの開始 ] をクリックします。
-
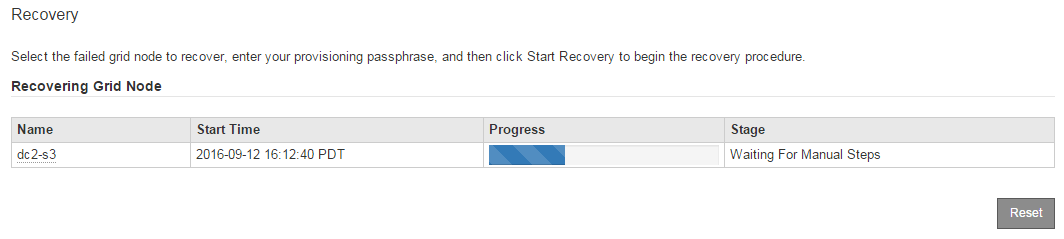
リカバリ中のグリッドノードテーブルで、リカバリの進行状況を監視します。

リカバリ手順 の実行中に [* リセット ] をクリックすると、新しいリカバリを開始できます。情報ダイアログボックスが表示され、手順 をリセットするとノードが不確定な状態のままになることが示されます。 
手順 をリセットしたあとにリカバリを再試行する場合は、次の手順でノードをインストール前の状態にリストアする必要があります。
-
* vmware * :導入した仮想グリッドノードを削除します。その後、リカバリを再開する準備ができたら、ノードを再導入します。
-
Linux: Linux ホスト上で次のコマンドを実行してノードを再起動します StorageGRID node force-recovery_node-name_
-
-
ストレージ・ノードが Waiting for Manual Steps ステージに進んだら ' リカバリ手順 の次のタスクに進み ' ストレージ・ボリュームを再マウントして再フォーマットします